코드트리 직접 코딩 감각 유지기 3. 알림톡과 GitHub 잔디로 루틴을 유지했습니다
이 글의 핵심은 CodeTree 알림톡, GitHub 잔디, Trail 진행률을 문제 풀이로 다시 돌아오는 장치로 사용한 과정입니다.
1편에서는 CodeTree 갭체크로 백트래킹 약점을 확인했습니다. 2편에서는 바로 고난도 백트래킹으로 가지 않고, Trail 0과 Trail 1에서 Python 기초 흐름을 다시 확인했습니다.
이번 3편의 기준은 조금 다릅니다. 약점을 알고, 기초 흐름도 다시 확인했다면, 그 다음에는 같은 경로로 계속 돌아올 수 있어야 합니다.
문제 풀이 루틴은 다음 날 다시 접속할 기준이 없으면 쉽게 끊겼습니다. 이번 글은 CodeTree의 알림톡, GitHub 잔디, Trail 진행률이 이 문제를 어떻게 줄였는지 정리합니다.
이번 기록은 완벽한 학습 성공담이 아니라, 학습이 끊기지 않도록 돌아오는 구조를 만든 기록입니다.
먼저 용어를 나누니 루틴 장치의 역할이 보였습니다
이번 글에서는 학습 루틴과 관련된 장치를 구분해서 봤습니다.
| 용어 | 쉬운 설명 | 이번 글에서의 의미 |
|---|---|---|
| 루틴 | 같은 행동을 반복할 수 있게 만든 흐름입니다 | 매번 새 결심을 하지 않아도 다시 문제 풀이로 돌아오는 구조입니다 |
| 알림톡 | 카카오톡으로 오는 학습 리마인더입니다 | 공부를 대신하지 않지만 다시 접속하게 만드는 신호가 됩니다 |
| GitHub 잔디 | GitHub 활동 기록이 날짜별로 보이는 화면입니다 | 문제 풀이 기록이 눈에 보이게 남는 장치입니다 |
| Trail 진행률 | CodeTree 학습 경로의 현재 진행 상태입니다 | 다음에 어디로 들어가야 할지 보여주는 기준입니다 |
| 학습 공백 | 며칠 동안 문제 풀이가 끊기는 상태입니다 | 다시 시작하는 비용을 크게 만드는 원인입니다 |
이 구분이 필요한 이유는 루틴을 의지만으로 설명하지 않기 위해서입니다. 이번에 확인한 것은 의지가 강해졌다는 이야기가 아니라, 다시 접속하게 만드는 장치가 생겼다는 점입니다.
GitHub 잔디는 학습 기록을 눈에 보이게 만들었습니다
CodeTree를 시작하고 먼저 체감한 변화는 기록이 보인다는 점이었습니다. 문제를 풀고 정답을 맞히면 GitHub 연동을 통해 기록이 남고, 그 기록이 잔디처럼 쌓였습니다.
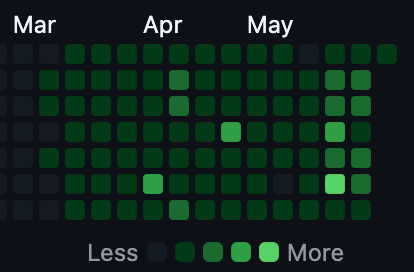
GitHub 잔디가 실력을 보장해주는 것은 아닙니다. 초록 칸이 많다고 해서 백트래킹 약점이 자동으로 해결되는 것도 아닙니다.
다만 습관을 만드는 단계에서는 효과가 있었습니다. 오늘 한 문제를 풀면 기록이 이어지고, 그냥 넘기면 빈칸이 남는다는 점이 바로 보였기 때문입니다.
문제 풀이 기록이 눈에 보이면 다음 행동의 문턱이 낮아집니다. 이번에는 GitHub 연동이 그 역할을 했습니다.
알림톡은 공부를 대신하지 않지만 다시 접속하게 만들었습니다
두 번째로 도움을 받은 장치는 CodeTree 학습 리마인더 알림톡이었습니다. 매일 카카오톡으로 학습 안내가 오니, 직접 문제를 풀어보는 시간을 완전히 잊고 지나가기 어려워졌습니다.
알림톡이 코드를 대신 써주지는 않습니다. 문제를 읽고, 조건을 나누고, 코드를 작성하는 일은 직접 해야 합니다.
하지만 시작 전의 미루는 시간을 줄이는 데는 도움이 됐습니다. 퇴근 후나 다른 일을 마친 뒤에는 문제 풀이 사이트를 여는 것부터 미루기 쉽습니다. 알림톡은 그 흐름을 한 번 끊어줬습니다.
이번에 중요한 것은 큰 동기부여가 아니었습니다. 한 문제라도 풀기 위해 다시 접속하는 작은 신호였습니다.
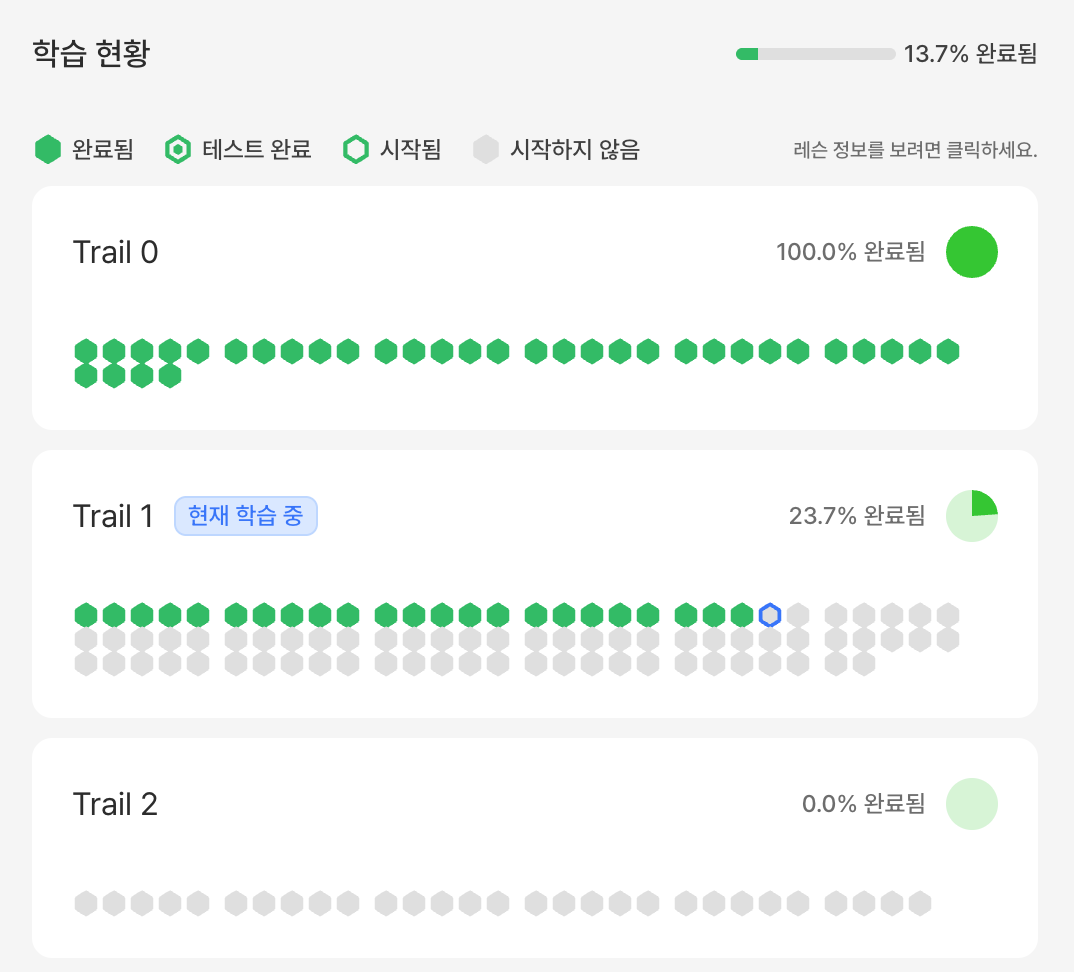
Trail 진행률은 다음 행동을 다시 정하게 해줬습니다
이번 주 학습 상태는 다음과 같았습니다.
| 항목 | 상태 | 의미 |
|---|---|---|
| Trail 0 | 완료 | 기초 시작 흐름을 끝까지 확인했습니다 |
| Trail 1 | 23.7% 진행 | 출력, 입출력, 연산자, 조건문, 반복문 등 기본 챕터를 이어가고 있습니다 |
| GitHub 잔디 | 기록 유지 | 문제 풀이가 눈에 보이는 기록으로 남았습니다 |
| 알림톡 | 수신 | 학습 공백을 줄이는 리마인더로 작동했습니다 |
숫자만 보면 큰 진도는 아닐 수 있습니다. 하지만 이번 회차에서는 많이 나아가는 것보다 끊기지 않는 것이 더 중요했습니다.
알고리즘 문제 풀이는 며칠만 쉬어도 손이 느려질 수 있습니다. 특히 백트래킹처럼 재귀 흐름과 상태 복구를 직접 설계해야 하는 유형은 감각이 끊기면 다시 시작하기가 더 어렵습니다.
Trail 진행률은 다음에 어디로 들어가야 하는지 보여줬습니다. 문제를 고르는 데 쓰는 에너지가 줄어든 점도 루틴 유지에 도움이 됐습니다.
진단과 실행 사이에는 돌아오는 장치가 필요했습니다
1편과 2편만으로는 아직 부족했습니다. 1편에서 약점을 찾고 2편에서 기초로 내려갔더라도, 며칠 뒤 다시 접속하지 않으면 학습은 기록으로만 남습니다.
그래서 이번 3편에서는 문제 풀이 성과보다 루틴 장치를 더 중요하게 봤습니다.
| 장치 | 역할 |
|---|---|
| 알림톡 | 다시 접속하라는 신호를 줍니다 |
| GitHub 잔디 | 접속한 결과를 눈에 보이게 남깁니다 |
| Trail 진행률 | 다음에 무엇을 할지 보여줍니다 |
세 장치가 합쳐지면 매번 "오늘 무엇을 해야 하지"를 새로 정하는 부담이 줄어듭니다. 자기주도 학습이라고 해서 모든 것을 의지로 해결할 필요는 없었습니다.
CodeTree는 문제 풀이와 루틴 장치가 함께 있었습니다
백준이나 프로그래머스도 알고리즘 문제를 풀기 좋은 서비스입니다. 문제 수가 많고, 원하는 유형을 골라 풀기 좋습니다.
다만 루틴을 유지하려면 스스로 결정해야 할 것이 많습니다. 오늘 어떤 유형을 풀지, 어떤 난이도를 고를지, 기록을 어디에 남길지, 며칠 쉬었을 때 어떻게 다시 시작할지까지 정해야 합니다.
CodeTree는 이 부분에서 조금 달랐습니다. Trail이 다음 학습 경로를 보여주고, 알림톡이 다시 들어오게 만들고, GitHub 연동이 기록을 남겼습니다.
이 장치들이 문제 풀이 실력을 대신하지는 않습니다. 하지만 독학에서 자주 무너지는 지점인 "다시 시작하기"를 줄여줬습니다.
참고한 다른 CodeTree 후기에서도 비슷한 흐름을 확인했습니다. 매일 완벽하게 이어가는 것보다, 공백이 생겼을 때 다시 들어오게 만드는 장치가 중요하다는 관점이었습니다.
앞으로는 긴 시간보다 자주 돌아오는 쪽을 우선합니다
이번 회차를 지나며 기준을 조금 바꿨습니다.
예전에는 문제 풀이를 하려면 긴 시간이 필요하다고 생각했습니다. 한 문제를 제대로 풀려면 충분한 시간이 있어야 하고, 시간이 애매한 날에는 아예 시작하지 않는 식이었습니다.
하지만 이 방식은 바쁜 주에 쉽게 끊깁니다. 그래서 앞으로는 짧게라도 자주 돌아오는 쪽을 우선하려고 합니다.
현재 남은 과제는 분명합니다.
| 남은 과제 | 이유 |
|---|---|
| Trail 1을 계속 진행합니다 | Python 기초 흐름을 더 안정화해야 합니다 |
| 1편에서 건너뛴 Backtracking 유형으로 돌아갑니다 | 진단한 약점을 다시 확인해야 합니다 |
| 루틴 장치가 실제로 유지되는지 봅니다 | 알림톡과 GitHub 잔디가 장기 학습에도 도움이 되는지 확인해야 합니다 |
이번 3편은 약점 해결 완료 기록이 아닙니다. 약점을 확인하고, 기초로 내려가고, 다시 돌아오는 구조를 붙인 기록입니다.
다음에 남길 증거는 더 분명합니다. Trail 1을 더 진행하고, 1편에서 건너뛰었던 백트래킹 유형을 다시 시도하겠습니다.
CodeTree 바로가기 https://www.codetree.ai/ko
해시태그 #코드트리 #문제해결 #직접코딩 #개발자루틴 #학습루틴 #알고리즘공부
이어 읽기
시리즈는 순서대로, 편집 추천은 맥락대로, 비슷한 주제는 태그 기준으로 정리합니다.
시리즈 전체
코드트리 직접 코딩 감각 유지기3/5편- 1.코드트리 직접 코딩 감각 유지기 1. 갭체크로 백트래킹 약점을 확인했습니다
- 2.코드트리 직접 코딩 감각 유지기 2. 백트래킹 전에 파이썬 기초를 다시 확인했습니다
- 3.코드트리 직접 코딩 감각 유지기 3. 알림톡과 GitHub 잔디로 루틴을 유지했습니다
- 4.코드트리 직접 코딩 감각 유지기 4. 북마크로 백트래킹 복습 루틴을 만들었습니다
- 5.코드트리 직접 코딩 감각 유지기 5. 한 달 갭체크 후기로 약점 변화를 확인했습니다
비슷한 주제의 글
태그가 겹치는 글입니다. 시리즈와 편집 추천에 이미 나온 글은 제외합니다.
LLM 공부 01. LLM은 검색기가 아니라 다음 토큰 생성기다
LLM을 내부 검색기나 외부 도서관으로 오해하지 않도록, 문장이 token으로 바뀌고 embedding, Transformer block, LM head, prefill/decode, KV cache를 거쳐 다음 token이 생성되는 흐름을 입문자 관점에서 정리합니다.
LLM 공부 02. 토큰이 비용을 만든다
Tokenizer가 문장을 token ID로 바꾸고 embedding table과 LM head가 vocabulary와 연결되는 구조를 설명하며, vocabulary 변화가 sequence length, KV cache, 사용자 토큰 비용 체감으로 이어지는 이유를 정리합니다.
LLM 공부 03. Transformer 안에서 문맥이 섞이는 방식
Embedding된 token 벡터가 Transformer block stack을 통과하며 self-attention, Q/K/V, causal mask, MLP/FFN, residual stream을 거쳐 다음 token 예측에 필요한 hidden state로 바뀌는 과정을 설명합니다.